Fun fact: nominations for Nobel prizes are kept secret for 50 years. Luckily, after that cooldown period they are publicly available. Anyone can browse the database and even make some infographics about geography and terrible gender bias of the prizes in pretty much any discipline.
This week was a Nobel Prize week in science, and the whole world became a bit more interested in cancer immunotherapy, laser physics, and directed protein evolution. As it happens fairly often recently, some debate arose about wether the chemistry prize is even about chemistry at all. I think Derek Lowe summarized it very well and I stick with his opinion that yes, it’s chemistry so suck it up round-bottom-flask fans and small-molecule lovers (disclaimer: I’m a med chemist by training).
Then I looked into the history of chemistry prizes. And, guess what, the trend of giving prizes for biochemistry can be traced right to the very beginning. In 1907 Eduard Buchner got the prize for cell-free fermentation leaving Le Chatelier and Canizzaro in the dust forever. In February, the same year Mendeleev died – with no Prize. That year he was supported by two nominators, as many as Buchner had. So it seems that biochemistry was always sexy in the eyes of the Nobel committee (and nominators). But to be sure let’s now look at the data!
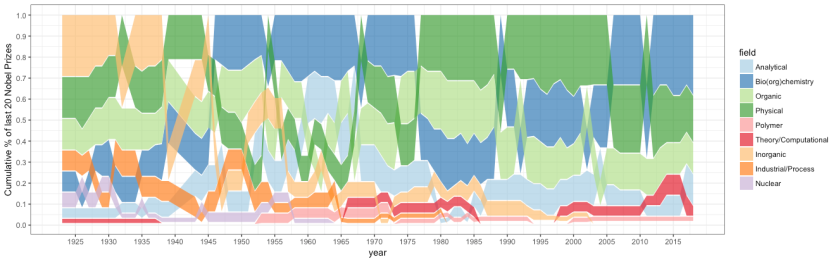
To get somewhat quantitative, I’ve tried to classify all the chemistry prizes into 9 categories (see the figure). To overcome name bias I looked only at the official formulation for what the prize was awarded. Sometimes I wasn’t sure so I assigned some prizes to two fields – both got a score of 0.5 that year. Here’s the resulting table so anyone can look and disagree with my classification. Finally, I aggregated the scores in 20-year moving buckets and ranked the chemistry subfields according to percentage of Nobel prizes they’d got. For ties average rank was assigned. So here’s the result:
Ranks of chemistry subfields according to number of Nobel prizes in the last 20 years (pdf)
As you can see, biochemistry and related disciplines have always been among favorites while inorganic, industrial, and nuclear chemistry’s Nobel scores were declining steadily. Organic and physical chemistries had their ups and downs but mostly stood at the top, while analytical chemistry was always in the middle. The ranks are, however, qualitative information. Here’s the bump chart with quantitative percentage data.
Fraction of Nobel prizes in chemistry subfields in the last 20 years (pdf)
Well, biochemistry is clearly dominating the last 20 years with the record share of 40% of Nobel prizes in chemistry, which is repetition of physical chemistry’s performance in the end of XX century. But this is not something completely new. From the end of World War 2 till late 70s biochemistry was regularly harvesting 25-30% of prizes.
One can argue that’s because there’s no separate Nobel prize for biology. But my point is that it’s not the guilt of biochemists that with all the advances in analytical, physical, theoretical, organic, inorganic, polymer, and nuclear chemistries they now can study complex living system as if these are just a bunch of molecules. Instead, it’s a great reason to celebrate that we have reached this level of reductionism. And saying that ribosomes, ion channels or GPCRs are not chemistry is like saying that we shouldn’t call iPhone a phone any more. One may be right semantically but the world won’t care.
Wow, it’s been almost a year since the last post. Here’s some non-science for getting me in shape.
It’s been a couple of weeks since the FIFA World Cup final. Amazing falls of favorites and rises of underdogs are what people always look for in such events. Croatia, who had barely qualified for the tournament showed a great performance until the very last game, losing only to the young France team. Discussing the team’s chances one can’t help but compare their countries’ population sizes. Indeed, isn’t it amazing that Croatia, a nation of 4.1 million people, could leave behind England (55 million), Russia (144 million), Argentina (44 million), and Nigeria (186 million)? Or is it not? Below is some semi-serious attempt to analyze population – football performance relationship. Continue reading “Big nations – better players?”
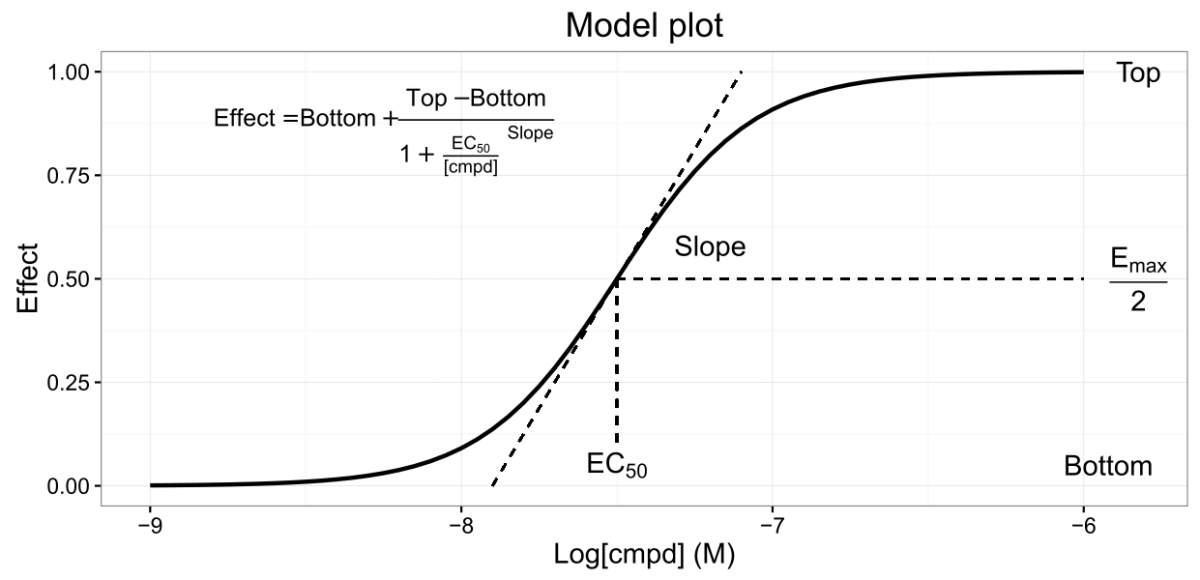
Since the grad school I have been using R for data analysis and (mainly) for preparation of nice plots. As with LaTeX, it was a pretty steep learning curve. But after a year or so I managed to become comfortable with writing a new script for each new experiment. After some time, however, I started feeling that it wasn’t enough. Many experiments were almost identical, so breeding 99%-similar scripts didn’t seem to be an efficient way of handling data. That’s when I first started to think about making ‘reusable’ apps for specific purposes. Continue reading “My first Shiny app: fitting sigmoid curves”
An interesting case study of a correct structure assignment for aquatolide appeared in JOC. It’s interesting from several points of view. First, it nicely shows how one can effectively use reach information from free induction decay (FID), which is lost (or masked) in Fourier-transformed spectra. Second, it emphasizes importance of data sharing and demonstrates crucial role of ‘research parasites‘ in scientific ecosystem. Third, the paper has seven-point manifest in the conclusions section. Continue reading “True power of 1D NMR”
It’s really entertaining to watch the (over)reaction of Twitter on the controversial editorial in NEJM about data sharing and open science. As usual, it’s pretty hysteric but has a potential to cause some real-world consequences. The problem is that the authors were reckless enough to use term “research parasites” for those scientists who use the data from other labs without conducting their own experiments. Continue reading “Research parasites”
Today chemical biology generates new high-throughput methods of studying biomolecules almost as quickly as organic chemists report total syntheses. Whole genome, transcriptome, proteome, lipidome, glycome etc. analyses are flourishing and delivering vast amounts of data. Bioinformaticist are trying to cope with the data flow by archiving them in various databases. This has led to a situation when the number and diversity of databases became incomprehensible for a human being. Continue reading “The database of databases”