Fun fact: nominations for Nobel prizes are kept secret for 50 years. Luckily, after that cooldown period they are publicly available. Anyone can browse the database and even make some infographics about geography and terrible gender bias of the prizes in pretty much any discipline.
This week was a Nobel Prize week in science, and the whole world became a bit more interested in cancer immunotherapy, laser physics, and directed protein evolution. As it happens fairly often recently, some debate arose about wether the chemistry prize is even about chemistry at all. I think Derek Lowe summarized it very well and I stick with his opinion that yes, it’s chemistry so suck it up round-bottom-flask fans and small-molecule lovers (disclaimer: I’m a med chemist by training).
Then I looked into the history of chemistry prizes. And, guess what, the trend of giving prizes for biochemistry can be traced right to the very beginning. In 1907 Eduard Buchner got the prize for cell-free fermentation leaving Le Chatelier and Canizzaro in the dust forever. In February, the same year Mendeleev died – with no Prize. That year he was supported by two nominators, as many as Buchner had. So it seems that biochemistry was always sexy in the eyes of the Nobel committee (and nominators). But to be sure let’s now look at the data!
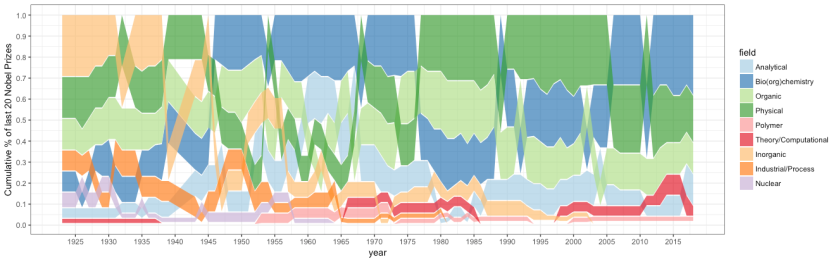
To get somewhat quantitative, I’ve tried to classify all the chemistry prizes into 9 categories (see the figure). To overcome name bias I looked only at the official formulation for what the prize was awarded. Sometimes I wasn’t sure so I assigned some prizes to two fields – both got a score of 0.5 that year. Here’s the resulting table so anyone can look and disagree with my classification. Finally, I aggregated the scores in 20-year moving buckets and ranked the chemistry subfields according to percentage of Nobel prizes they’d got. For ties average rank was assigned. So here’s the result:
Ranks of chemistry subfields according to number of Nobel prizes in the last 20 years (pdf)
As you can see, biochemistry and related disciplines have always been among favorites while inorganic, industrial, and nuclear chemistry’s Nobel scores were declining steadily. Organic and physical chemistries had their ups and downs but mostly stood at the top, while analytical chemistry was always in the middle. The ranks are, however, qualitative information. Here’s the bump chart with quantitative percentage data.
Fraction of Nobel prizes in chemistry subfields in the last 20 years (pdf)
Well, biochemistry is clearly dominating the last 20 years with the record share of 40% of Nobel prizes in chemistry, which is repetition of physical chemistry’s performance in the end of XX century. But this is not something completely new. From the end of World War 2 till late 70s biochemistry was regularly harvesting 25-30% of prizes.
One can argue that’s because there’s no separate Nobel prize for biology. But my point is that it’s not the guilt of biochemists that with all the advances in analytical, physical, theoretical, organic, inorganic, polymer, and nuclear chemistries they now can study complex living system as if these are just a bunch of molecules. Instead, it’s a great reason to celebrate that we have reached this level of reductionism. And saying that ribosomes, ion channels or GPCRs are not chemistry is like saying that we shouldn’t call iPhone a phone any more. One may be right semantically but the world won’t care.
Wow, it’s been almost a year since the last post. Here’s some non-science for getting me in shape.
It’s been a couple of weeks since the FIFA World Cup final. Amazing falls of favorites and rises of underdogs are what people always look for in such events. Croatia, who had barely qualified for the tournament showed a great performance until the very last game, losing only to the young France team. Discussing the team’s chances one can’t help but compare their countries’ population sizes. Indeed, isn’t it amazing that Croatia, a nation of 4.1 million people, could leave behind England (55 million), Russia (144 million), Argentina (44 million), and Nigeria (186 million)? Or is it not? Below is some semi-serious attempt to analyze population – football performance relationship. Continue reading “Big nations – better players?”
It’s been a little over two years since the first attempt to use CRISPR-Cas9 to correct beta-thalassemia in non-viable human embryos. At the time that manuscript was rejected from both Nature and Science on ethical ground. Today the ethical consensus seems to have settled to that modifying human germline cells is OK unless you want to enhance otherwise normal human embryo. So now everyone is doing that anyway. And the last ethical barrier to CRISPR-babies is actual implantation of genetically corrected embryo in clinical settings.
In the paper linked in the beginning, the authors corrected the mutation of cardiac myosin-binding protein C (cMyBP-C), a key factor in 40% of hypertrophic cardiomyopathy (HCM). HCM in turn is a frequent cause of sudden death in young athletes. Current state-of-the-art for preventing this disease is preimplantation genetic diagnosis (PGD) in the context of in vitro fertilization (IVF).
Long story short, the team led by Prof. Mitalipov from OHSU has seemingly figured out how to perform gene editing in the safest way. The first key trick was to deliver pre-formed Cas9-sgRNA ribonucleoproteine (not the plasmids or viruses). And the second trick was to do that via microinjection simultaneously with fertilization. The timing was crucial as the editing had to be done before DNA duplication machinery would start running full-speed.
The most positive news is that in zygotes DNA repair mechanism was much more well-behaving than in induced stem cells. But at the same time it’s a rather tricky point. So far we don’t know how similar DNA repair efficiencies are in different people. It’s hard to extrapolate anything from n = 1 sample. A more mixed news is that embryos used mother’s DNA as a template for repair, rather than external DNA supplied together with Cas9-sgRNA complex. This prompted some relief that there will be no ‘designer-babies’ in the nearest future (more on that later). But this also means the technology won’t be able to edit homozygous embryos. So overall, the answer to the question ‘is CRISPRing embryos a clinic-ready technology?’ is usual ‘more studies are needed’.
If you think about it, inability to use external DNA for repairing Cas9-cut genes casts a significant shadow over CRISPR perspectives for reproduction biology. That means the technology is very close to being redundant to IVF/PGD combo. The only advantage it will provide is, in authors’ words:
targeted gene correction can potentially rescue a substantial portion of mutant human embryos, thus increasing the number of embryos available for transfer
Since there is only one embryo to be implanted anyway, having to choose between, let’s say, 10 and (up to) 20 is not such a big deal. But who knows, maybe this limitation is just a matter of optimization and not another biological dogma. Again, n = 1 is not a sample size to draw serious conclusions.
Regarding the ‘designer-babies’, however, I wouldn’t be too comforted by the Mitalipov’s paper. Because the definition of ‘design’ can be different. Many physical features can be easily manipulated by doing gene knockout, with no external DNA needed. The question is though ‘Do we really need to enhance physical or mental parameters of humans in the world full of robots?‘ Surprisingly or not, many people still think that we do. That’s why bioethics will remain a major obstacle in reproductive biology, even in China. I’ll leave this quote (about PGD/IVF) as a nice illustration of current state of ethical consensus on genetic manipulation with human embryos:
[…] some families ask to weed out the mutation that renders many Asians unable to process alcohol, something that could affect the ability to take part in the often alcohol-fuelled Chinese business lunches. “They want their son to be able to drink,” says Lu. “We say no.”
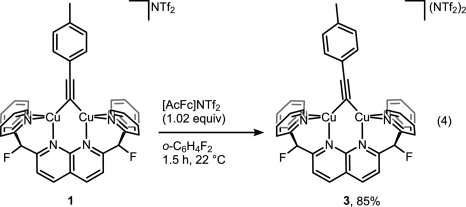
It is amazing how Huisgen azide-alkyne cycloaddition, once resurrected and reinvented by K. Barry Sharpless, generated so many application papers while we are still digging to understand its copper-catalyzed mechanism.
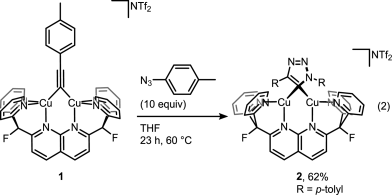
A recent JACS paper from Don Tilley lab sheds some more light on the catalytic cycle. And it’s not that easy as setting up the reaction itself. Disrupting catalytic cycle in step-by-step fashion is a tricky business but it was beautifully done in this study. First, trapping elusive cycloadduct within dinuclear copper complex:
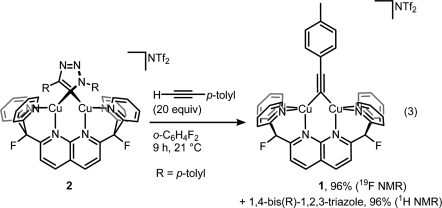
Then displacing it with a fresh alkyne to get the product and the complex ready for another catalytic cycle:
But then look at the scheme below, which is arguably the least dramatic change one can imaging from a chemical transformation (involving organic compounds).
For those still scratching their head about what did actually happen here, it’s a one-electron oxidation of Cu(I)-Cu(I) dicopper complex into mixed-valence Cu(I)-Cu(II). That slight tilt of the bridging alkyne ligand seems to be the only indicator that reaction indeed took place without much of competing disproportionation or whatever could happen to the complex. Yes, it takes X-ray crystallography to prove that, and I wonder if Micah Ziegler, the first author, a priori knew what to look for to monitor the reaction success. EPR? Cyclic voltammetry? Maybe color change was enough?[1]
Anyway, attempts to get the mixed complex 3 to react with tolylazide didn’t succeed. So authors concluded that CuAAC does not involve mixed-valence dicopper complexes. In addition, they excluded a bunch of alternatively proposed intermediates. This was in fact contradicting with earlier results published by Jin et al of Bertrand lab. The key difference between papers was that in the latest study authors forced two copper atoms to sit close to each other, while Jin et al used mononuclear copper complex to initiate the reaction [2]. This may bring up a discussion of what study is more relevant for ‘real world’ cycloaddition. I wonder more, however, if knowing the exact mechanism will help one to improve the reaction in any way. It already is pretty well-optimized and reliable (to a point).
More generally, it seems like the dissociation of practical application from (strictly unambiguous) theoretical explanation is a genuine feature of science. Take for instance CRISPR-Cas9, which leading experts are still trying to understand how it works in native systems (i.e. bacteria) while other scientists are ready to tweak human embryos with it.
[1] 19F NMR had enough difference due to different stoichiometry of triflimide anions.
[2] It still might be that both results are ‘right’ and one intermediate can turn into the other.
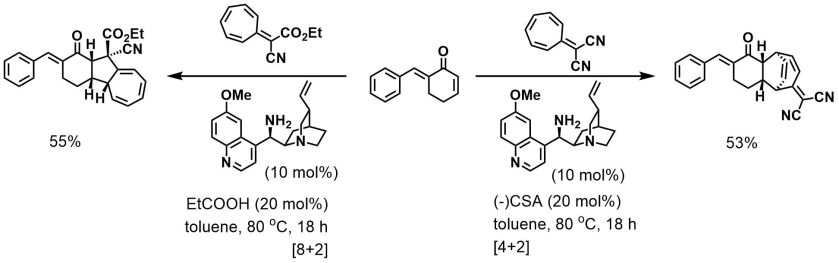
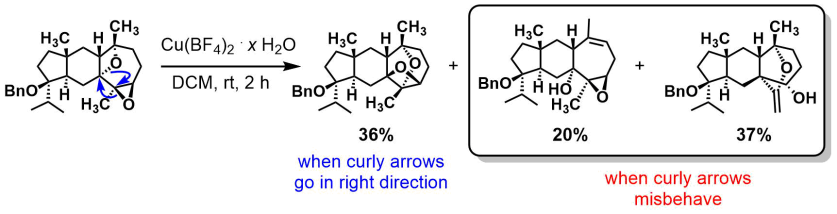
There are whole bunch of messy electrocyclic reactions in the paper and nice projections explaining diastereoselectivity. They made me nostalgic about reading OC texbooks.
Want something even cooler, here’s a dyotropic reaction! Characterizing the side-products must have been a lot of fun. As well as monitoring the progress (the major undesired product had the same Rf as the starting material, and good luck with crude NMR). Heads up from amphoteros.
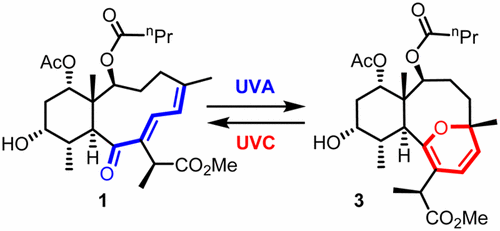
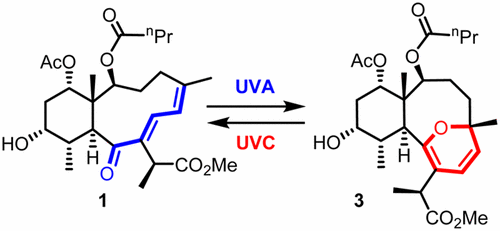
Was this reversible photo-switch discovered by accidentally shining a wrong UV lamp onto the final product? The authors say it was expected. [Note: UVA = 350 nm; UVC = 254 nm]. TOC graphic:
OK, enough electrocyclic reactions. Here’s some C-H activation work from Jin-Quan Yu lab. From [phthalimide-protected] alanine to [phthalimide-protected] substituted phenylalanines in one step! The conditions are somewhat peculiar though. A lot of silver (and quite a lot of palladium) was consumed for this to happen.
Tellurium is not very popular among chemists (and even less among anybody else for that matter), so each successful use of it is worth attention. The authors of this paper managed to find an application for sodium hydrotelluride. As an excuse they wrote this last sentence of discussion: ‘Reduction of the α-azido ketone 31 with PPh3, as in the Staudinger reduction, followed by stirring in air could not deliver 34 in our hands.’
Another unusual thing in the paper is the open call for collaborations: ‘For now, gram scale of 30 and more than 100 mg of 34 [12,12′-azo-13,13′-diepi-Ritterazine N] are available for any interested collaborators.’ I felt obliged to spread the word.
Since I’m not that long in diabetes business, two new Cell papers from Collombat and Kubicek labs looked quite sensational for me. Both are the products of multi-centered collaborations, and both report regeneration of insulin-producing beta-cells in vivo with small molecules.
As I learned from introductions, reprogramming of pancreatic alpha cells (glucagon-secreting) into beta cells is a sort of a Holy Grail of regenerative medicine for diabetes treatment. Naturally, first attempts to reprogramming were performed with aid of transcription factors. But pretty soon small molecules kicked in. These were kinase inhibitors and chromatin-altering probes from Stuart Schreiber lab, resveratrol (of course!), and peptide hormone betatrophin. OK, the last one doesn’t count, and it’s not a small molecule anyway. What’s unusual about the latest Cell papers, is that they describe reprogramming by small molecules acting pretty high upstream from direct gene regulation [1]. Both papers involve messing with GABAA receptor signaling.
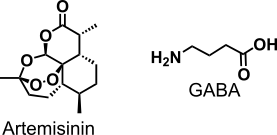
Let’s start with the Kubicek lab paper, which found that common (yet Nobel-winning) malaria drug, artemisinin, can make pancreatic alpha cells to secret insulin. The authors identified artemisinin and its metabolite dehydroartemisinin from a library of 280 existing drugs [2]. After they found that the drugs induce insulin secretion, they identified gephyrin as the most likely target. Then, via electrophysiology and a series of inhibitory tests, they linked gephyrin-mediated activity to GABAA receptor signaling. Known agonists of GABAA, however, didn’t increase insulin secretion as much as artemisinin (after 72 h treatment of cells). The drug then increased mass of beta cells islets in zebrafish, healthy and diabetic mice (while reducing basal glucose level in the last ones). Finally, it altered gene expression in human alpha cells and increased insulin secretion by the islets. Frankly, the figure 7A-C, which is supposed to convince in the last effect, raises some questions as data look cherry-picked from different donors. But authors do address that by briefly mentioning donor-to-donor variability. And it’s not surprising at n = 6 sample size.
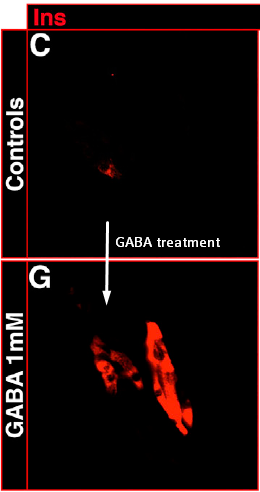
The paper from Collombat lab branches from the screening results of the first one. Once researchers noticed that activation of GABA signaling correlates with alpha-to-beta conversion, they thought “why not injecting plain ol’ GABA into mice?” And miraculously this simple idea worked. Just look at the jaw-dropping figures 1B-D! Figure S7C,G (below) can somewhat give you the feeling, but go check out the main paper, you won’t be disappointed.
Figure S7 fragment showing increase in insulin-producing cells from rat pancreas. I assume scale bars, if they were present, would be equal (Ben-Othman et al paper)
Here are the main results: daily injections of GABA at 250 μg/kg over three months convert pancreatic alpha cells into beta. But what’s even more exciting is that the new alpha cells are continuously being produced to compensate for those that were converted into beta! They even caught small fraction of cells in some transitional state, where they secret both glucagon and insulin. I particularly liked the discussion section where authors warn that before you, all excited, rush to inject diabetic patients with GABA think why there’s not enough beta cells in the first place. Yes, it is patient’s immune system that attacks her own beta cells. So before this approach makes into clinic one needs to figure out that autoimmune component of type 1 diabetes.
In a sum we have two great papers with rock-solid mouse data and some exciting preliminary results in human beta cells. Let’s see where it will end up. Regardless of the future success, isn’t it amazing how small, simple, and seemingly well-known molecules like GABA (and artemisinin for that matter) can upturn human cells identity?
[1] OK, authors do not strictly claim reprogramming as the identity of cells doesn’t change completely from alpha to beta, but their secretory activity is definitely flipped.
[2] Side note: check out this sexy acoustic liquid handler they used.
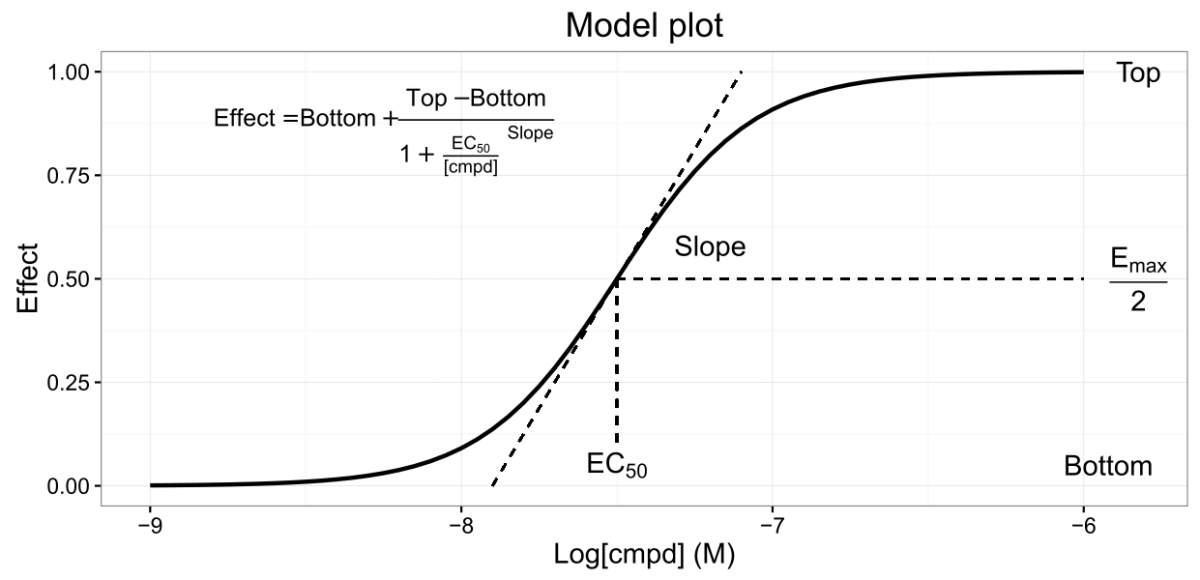
Since the grad school I have been using R for data analysis and (mainly) for preparation of nice plots. As with LaTeX, it was a pretty steep learning curve. But after a year or so I managed to become comfortable with writing a new script for each new experiment. After some time, however, I started feeling that it wasn’t enough. Many experiments were almost identical, so breeding 99%-similar scripts didn’t seem to be an efficient way of handling data. That’s when I first started to think about making ‘reusable’ apps for specific purposes. Continue reading “My first Shiny app: fitting sigmoid curves”
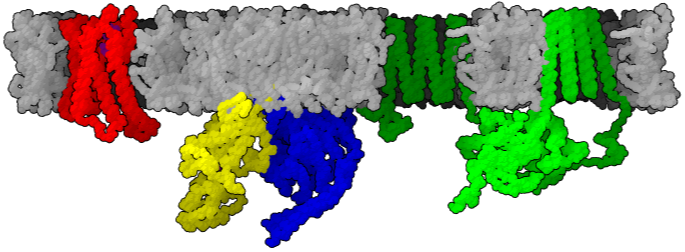
It’s almost four years since the Nobel prize in chemistry went to Brian Kobilka and Robert Lefkowitz for their contribution in our understanding of G protein-coupled receptor (GPCR) signaling. They did their most exciting work by studying β2 adrenergic receptor (β2AR). Yet, despite the titanic efforts, the receptor still holds lots of secrets from us. Continue reading “β2AR: old horse’s new tricks”
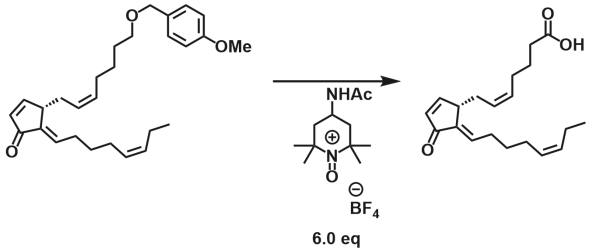
Nicolaou et al. does some medicinal chemistry on prostaglandins. Take a look at this Bobbit‘s salt protocol for deprotection/oxidation combo. It seems like they overload the reaction, compared to the original paper, which used 3 equivalents of the oxidant, but who cares if it works?
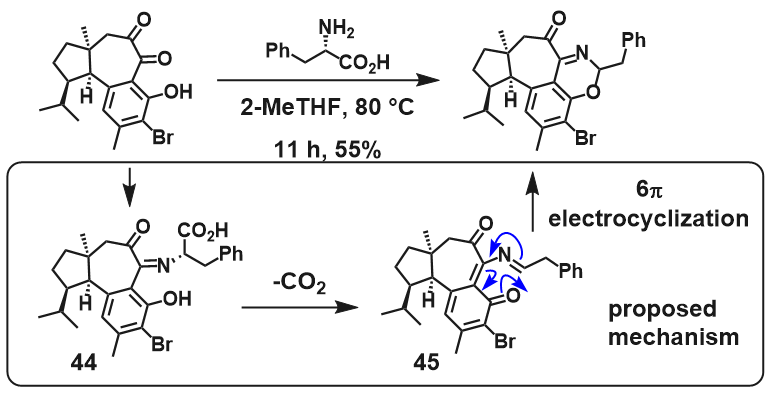
I’m not sure I would buy the proposed mechanism for the conversion below. The authors skip ‘−H2‘ step and get away with it by simply writing “the imine intermediate 44 […] underwent tautomerization and a key decarboxylation to generate 45 with higher oxidation state.” Something else is clearly happening under that −CO2 arrow and it’s not mere tautomerization.